Redis数据结构
redis基本的数据结构包括:字符串String、字典Hash、列表List、集合Set、有序集合SortedSet。
如果你是Redis中高级用户,还需要加上下面几种数据结构 HyperLogLog、Geo、Pub/Sub。
另外,Reids还有像 Redis Module,BloomFilter,RedisSearch,Redis-ML 等高级使用时会用到的数据结构。
Redis基本操作
字符串处理
set / get
1
2
3
4
5
6
7
8
9
10
|
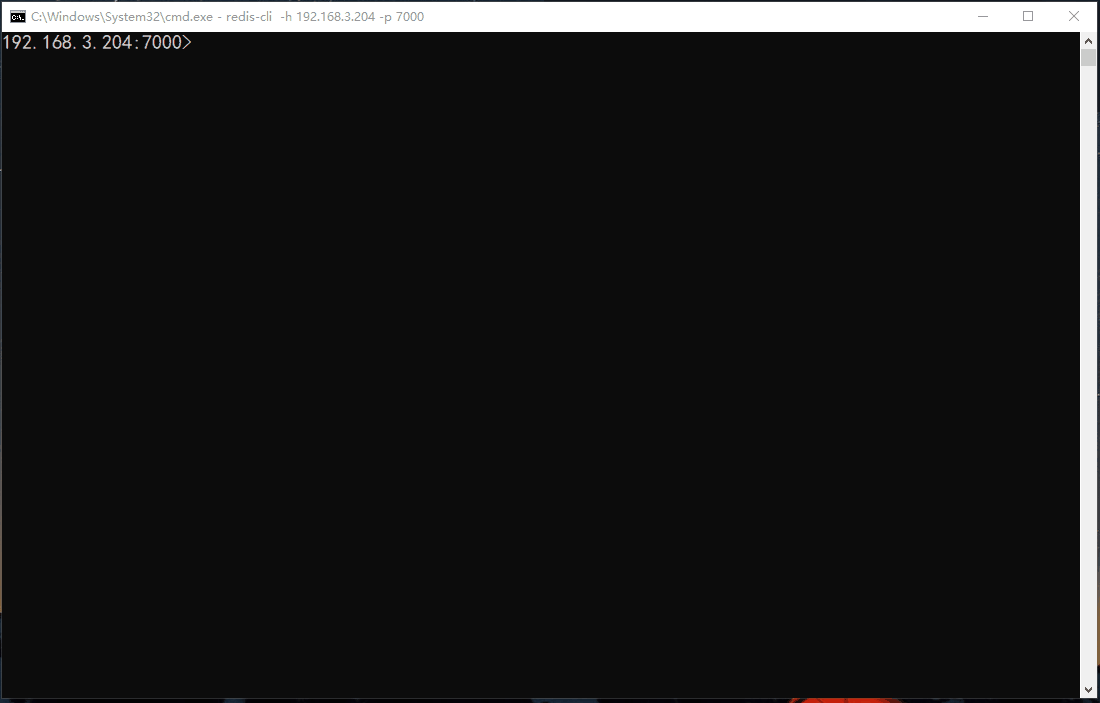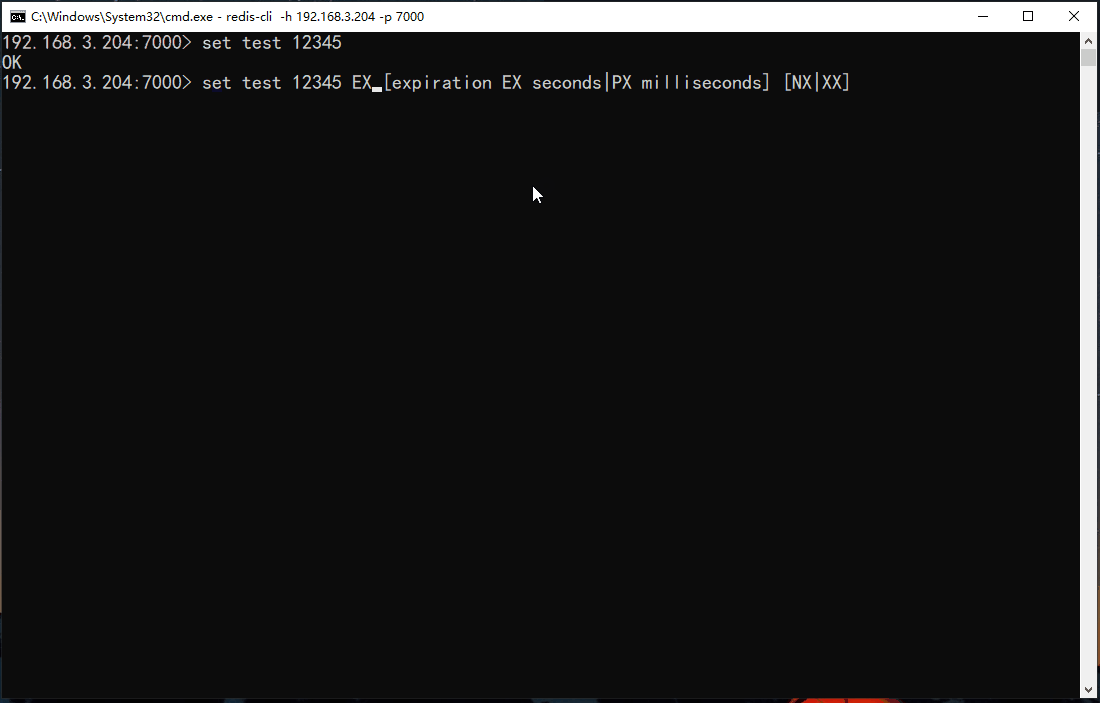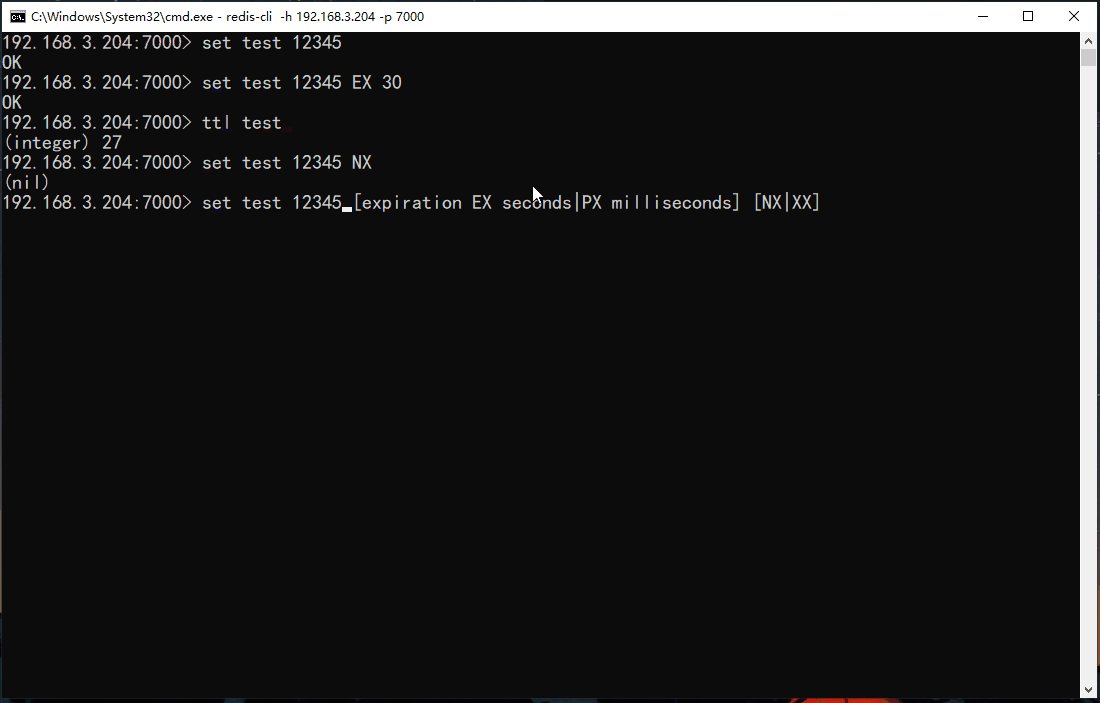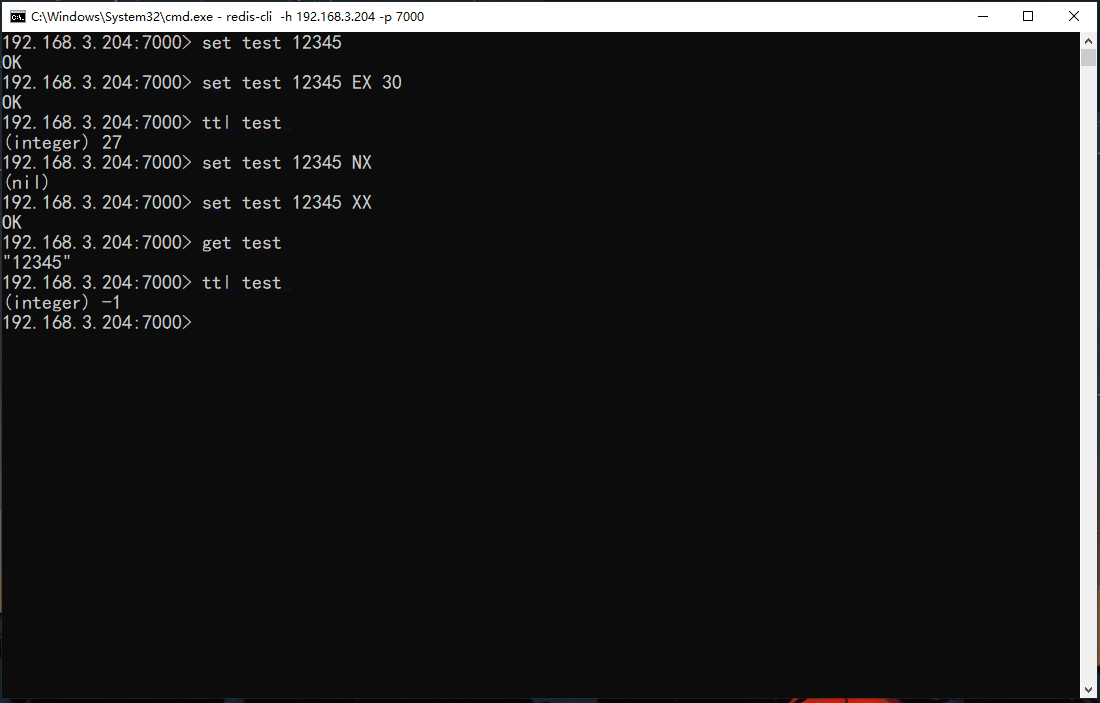
# 设置键的值,永不过期
set key value
# 设置键值,过期时间为30秒
set key value EX 30
# 设置键值,过期时间为3000毫秒
set key value PX 3000
# 只有键key不存在的时候才会设置key的值
set key value NX
# 只有键key存在的时候才会设置key的值
set key value XX
|
mset / mget
MSET 命令设置多个 key 的值为各自对应的 value。MSET 像 SET 一样,会用新值替换旧值。如果你不想覆盖旧值,可以使用 MSETNX。
MSET 是原子操作,所有 key 的值同时设置。客户端不会看到有些 key 值被修改,而另一些 key 值没变。
1
2
3
4
5
6
7
8
|
192.168.3.204:7000> mset key1 val1 key2 val2 key3 val3
OK
192.168.3.204:7000> get key1
"val1"
192.168.3.204:7000> get key2
"val2"
192.168.3.204:7000> get key3
"val3"
|
MGET 命令返回所有(一个或多个)给定 key 的值,值的类型是字符串。 如果给定的 key 里面,有某个 key 不存在或者值不是字符串,那么这个 key 返回特殊值 nil 。
1
2
3
4
5
|
192.168.3.204:7000> mget key1 key2 key3 nonexist-key4
1) "val1"
2) "val2"
3) "val3"
4) (nil)
|
incr / decr / incrby / decrby
INCR 命令将 key 中储存的数字值增一。
如果 key 不存在,那么 key 的值会先被初始化为 0 ,然后再执行 INCR 操作。
如果值包含错误的类型,或字符串类型的值不能表示为数字,那么返回一个错误 ERR ERR hash value is not an integer。
本操作的值限制在 64 位(bit)有符号数字表示之内。
1
2
3
4
5
6
7
8
9
10
|
192.168.3.204:7000> set key1 100
OK
192.168.3.204:7000> incr key1
(integer) 101
192.168.3.204:7000> incrby key1 3
(integer) 104
192.168.3.204:7000> set key2 test
OK
192.168.3.204:7000> incr key2
(error) ERR value is not an integer or out of range
|
append
APPEND 命令用于为指定的 key 追加值。
如果 key 已经存在并且是一个字符串, APPEND 命令将 value 追加到 key 原来的值的末尾。
如果 key 不存在, APPEND 就简单地将给定 key 设为 value ,就像执行 SET key value 一样。
1
2
3
4
5
6
|
192.168.3.204:7000> set key1 hello
OK
192.168.3.204:7000> append key1 liwenbo
(integer) 12
192.168.3.204:7000> get key1
"helloliwenbo"
|
散列表
hset / hget / hdel / hmset / hmget
Hset 命令用于为存储在 key 中的哈希表的 field 字段赋值 value 。如果哈希表不存在,一个新的哈希表被创建并进行 HSET 操作。
如果字段(field)已经存在于哈希表中,旧值将被覆盖。
Redis 4.0之前,使用Hmset一次设置多个field /vlaue,而从 Redis 4.0 起,HSET 可以一次设置一个或多个 field/value 对,HMSET 被废弃。
1
2
3
4
5
6
7
8
9
10
11
12
13
|
192.168.3.204:7000> hset myhash field1 val1 field2 val2
(integer) 0
192.168.3.204:7000> hget myhash field1
"val1"
192.168.3.204:7000> hget myhash field2
"val2"
192.168.3.204:7000> hmget myhash field1 field2
1) "val1"
2) "val2"
192.168.3.204:7000> hdel myhash field1
(integer) 1
192.168.3.204:7000> hget myhash field1
(nil)
|
hkeys / hvals
HKEYS 返回存储在 key 中哈希表的所有域(field)。当 key 不存在时,返回空表。
HVALS 命令返回哈希表所有域(field)的值。
1
2
3
4
5
6
7
8
9
10
|
192.168.3.204:7000> hset myhash field1 val1 field2 val2 field3 val3
(integer) 3
192.168.3.204:7000> hkeys myhash
1) "field1"
2) "field2"
3) "field3"
192.168.3.204:7000> hvals myhash
1) "val1"
2) "val2"
3) "val3"
|
hexists
检查存储在 key 中的哈希表的域(field)是否存在
1
2
3
4
|
192.168.3.204:7000> hexists myhash field1
(integer) 1
192.168.3.204:7000> hexists myhash field0
(integer) 0
|
hgetall
HGETALL 命令用于返回存储在 key 中的哈希表中所有的域和值。
在返回值里,紧跟每个域(field name)之后是域的值(value),所以返回值的长度是哈希表大小的两倍。
1
2
3
4
5
6
7
|
192.168.3.204:7000> hgetall myhash
1) "field1"
2) "val1"
3) "field2"
4) "val2"
5) "field3"
6) "val3"
|
hscan
HSCAN 命令用于遍历哈希表中的键值对。
redis HSCAN 命令基本语法如下:
1
|
HSCAN key cursor [MATCH pattern] [COUNT count]
|
- cursor - 游标。
- pattern - 匹配的模式。
- count - 指定从数据集里返回多少元素,默认值为 10 。
1
2
3
4
5
6
7
8
|
192.168.3.204:7000> hscan myhash 0 MATCH field* COUNT 10
1) "0"
2) 1) "field1"
2) "val1"
3) "field2"
4) "val2"
5) "field3"
6) "val3"
|
关于cursor游标和pattern,参加键操作中的说明。
列表
lpush / rpush
LPUSH 用于将一个或多个值插入到列表key 的头部。如果 key 不存在,那么在进行 push 操作前会创建一个空列表。
如果 key 对应的值不是 list 类型,那么会返回一个错误。
可以使用一个命令把多个元素 push 进入列表,只需在命令末尾加上多个指定的参数。
元素按在参数中出现的顺序,从左到右依次插入到 list 的头部。
所以对于这个命令例子 LPUSH mylist a b c,返回的列表是 c 为第一个元素, b 为第二个元素, a 为第三个元素。
该操作返回执行push操作后列表的长度。 rpush与lpush功能一样,区别在于rpush是从右侧插入。
1
2
3
4
|
192.168.3.204:7000> lpush mylist a a b b c c d d e f g
(integer) 11
192.168.3.204:7000> llen mylist
(integer) 11
|
lpop / rpop
LPOP 命令用于删除并返回存储在 key 中的列表的第一个元素。 RPOP 用于移除并返回列表 key 的最后一个元素。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
192.168.3.204:7000> lpush mylist a a b b c c d d e f g
(integer) 11
192.168.3.204:7000> llen mylist
(integer) 11
192.168.3.204:7000> lpop mylist
"g"
192.168.3.204:7000> llen mylist
(integer) 10
192.168.3.204:7000> lrange mylist 0 -1
1) "f"
2) "e"
3) "d"
4) "d"
5) "c"
6) "c"
7) "b"
8) "b"
9) "a"
10) "a"
|
llen
LLEN 用于返回存储在 key 中的列表长度。 如果 key 不存在,则 key 被解释为一个空列表,返回 0 。 如果 key 不是列表类型,返回一个错误。
1
2
3
4
5
6
7
8
9
10
|
192.168.3.204:7000> lpush mylist a b c d
(integer) 4
192.168.3.204:7000> llen mylist
(integer) 4
192.168.3.204:7000> llen nolist
(integer) 0
192.168.3.204:7000> set nolist astring
OK
192.168.3.204:7000> llen nolist
(error) WRONGTYPE Operation against a key holding the wrong kind of value
|
lrange
LRANGE 用于返回列表中指定区间内的元素,区间以偏移量 START 和 END 指定。 其中 0 表示列表的第一个元素, 1 表示列表的第二个元素,以此类推。 你也可以使用负数下标,以 -1 表示列表的最后一个元素, -2 表示列表的倒数第二个元素,以此类推。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
192.168.3.204:7000> lpush mylist a b c d
(integer) 4
192.168.3.204:7000> lrange mylist 0 -1
1) "d"
2) "c"
3) "b"
4) "a"
192.168.3.204:7000> lrange mylist 1 3
1) "c"
2) "b"
3) "a"
192.168.3.204:7000> lrange mylist -2 -3
(empty list or set)
192.168.3.204:7000> lrange mylist -3 -2
1) "c"
2) "b"
|
blpop / brpop
BLPOP 命令移出并获取列表的第一个元素, 如果列表没有元素会阻塞列表直到等待超时或发现可弹出元素为止。它是 LPOP 的阻塞版本。
当给定多个 key 参数时,按参数 key 的先后顺序依次检查各个列表,弹出第一个非空列表的头元素。BLPOP的语法是
1
|
BLPOP key [key ...] timeout
|
**阻塞行为:**如果所有给定 key 都不存在或包含空列表,那么 BLPOP 命令将阻塞连接, 直到有另一个客户端对给定的这些 key 的任意一个执行 LPUSH 或 RPUSH 命令为止。
当 BLPOP 命令引起客户端阻塞并且设置了一个非零的超时参数 timeout 的时候, 若经过了指定的 timeout 仍没有出现一个针对某一特定 key 的 push 操作,则客户端会解除阻塞状态并且返回 nil 。
下面是一个blpop使用的示例:

集合
sadd / srem
Sadd 命令将一个或多个成员元素加入到集合中,已经存在于集合的成员元素将被忽略。
假如集合 key 不存在,则创建一个只包含被添加的元素作为成员的集合。当集合 key 不是集合类型时,返回一个错误。
SREM 在集合中删除指定的元素。如果指定的元素不是集合成员则被忽略。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
192.168.3.204:7000> sadd myfruits apple banana
(integer) 2
192.168.3.204:7000> smembers myfruits
1) "banana"
2) "apple"
192.168.3.204:7000> sadd myfruits apple orange
(integer) 1
192.168.3.204:7000> smembers myfruits
1) "banana"
2) "apple"
3) "orange"
192.168.3.204:7000> srem myfruits apple
(integer) 1
192.168.3.204:7000> smembers myfruits
1) "banana"
2) "orange"
|
spop
SPOP 命令用于从集合 key中删除并返回一个或多个随机元素(不知道会删除哪个元素)。
这个命令和 SRANDMEMBER 相似, SRANDMEMBER 只返回随机成员但是不删除这些返回的成员。
参数 count 从 Redis 3.2 起可用。
1
2
3
4
5
6
7
8
9
10
11
12
|
192.168.3.204:7000> sadd myset a b c d e f
(integer) 6
192.168.3.204:7000> spop myset
"f"
192.168.3.204:7000> spop myset
"a"
192.168.3.204:7000> spop myset 3
1) "c"
2) "b"
3) "e"
192.168.3.204:7000> smembers myset
1) "d"
|
排序集合
zadd / zrem
ZADD 命令用于将一个或多个 member 元素及其 score 值加入到有序集 key 当中。
如果某个 member 已经是有序集的成员,那么更新这个 member 的 score 值,并通过重新插入这个 member 元素,来保证该 member 在正确的位置上。
如果有序集合 key 不存在,则创建一个空的有序集并执行 ZADD 操作。
当 key 存在但不是有序集类型时,返回一个错误。score 值可以是整数值或双精度浮点数,score 可为正也可以为负。
ZADD的语法定义为:
1
|
ZADD key [NX|XX] [CH] [INCR] score member [score member …]
|
ZREM 用于删除排序集合中的元素。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
192.168.3.204:7000> zadd myset 1000 "google" 800 "baidu" 500 "sina" 300 "sohu"
(integer) 4
192.168.3.204:7000> zrange myset 0 -1 withscores
1) "sohu"
2) "300"
3) "sina"
4) "500"
5) "baidu"
6) "800"
7) "google"
8) "1000"
192.168.3.204:7000> zrem myset sohu
(integer) 1
192.168.3.204:7000> zrange myset 0 -1 withscores
1) "sina"
2) "500"
3) "baidu"
4) "800"
5) "google"
6) "1000"
|
zrange / zrevrange
ZRANGE 命令返回有序集中,指定区间内的成员,其中成员的按分数值递增(从小到大)来排序,具有相同分数值的成员按字典序(lexicographical order )来排列。
如果你需要成员按值递减(从大到小)来排列,请使用 ZREVRANGE命令。
1
|
ZRANGE key start stop [WITHSCORES]
|
下标参数 start 和 stop 都以 0 为底,也就是说,以 0 表示有序集第一个成员,以 1 表示有序集第二个成员,以此类推。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
192.168.3.204:7000> zadd myset 1000 "google" 800 "baidu" 500 "sina" 300 "sohu"
(integer) 4
192.168.3.204:7000> zrange myset 0 1000
1) "sohu"
2) "sina"
3) "baidu"
4) "google"
192.168.3.204:7000> zrange myset 0 800 withscores
1) "sohu"
2) "300"
3) "sina"
4) "500"
5) "baidu"
6) "800"
7) "google"
8) "1000"
|
zscore 命令用于返回有序集 key.中成员 member 的分数。
1
2
|
192.168.3.204:7000> zscore myset baidu
"800"
|
zrangebyscore / zrevrangebyscore
Zrangebyscore 返回有序集合中指定分数区间的成员列表。有序集成员按分数值递增(从小到大)次序排列。
具有相同分数值的成员按字典序来排列(该属性是有序集提供的,不需要额外的计算)。
默认情况下,区间的取值使用闭区间 (小于等于或大于等于),你也可以通过给参数前增加 ( 符号来使用可选的开区间 (小于或大于)。
可选的LIMIT参数指定返回结果的数量及区间(类似SQL中SELECT LIMIT offset, count)。注意,如果offset太大,定位offset就可能遍历整个有序集合,这会增加O(N)的复杂度。
zrangebyscore 命令格式如下:
1
|
ZRANGEBYSCORE key min max [WITHSCORES] [LIMIT offset count]
|
下面是一个zrangebyscore的使用例子
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
192.168.3.204:7000> zadd myset 1000 "google" 800 "baidu" 500 "sina" 300 "sohu"
(integer) 4
192.168.3.204:7000> zrange myset 0 -1 withscores
1) "sohu"
2) "300"
3) "sina"
4) "500"
5) "baidu"
6) "800"
7) "google"
8) "1000"
192.168.3.204:7000> zrangebyscore myset 300 800 withscores limit 0 2
1) "sohu"
2) "300"
3) "sina"
4) "500"
|
键操作
keys
KEYS 命令用于查找所有符合给定模式 pattern 的 key 。尽管这个操作的时间复杂度是 O(N), 但是常量时间相当小。
例如,在一个普通笔记本上跑 Redis,扫描 100 万个 key 只要40毫秒。
Warning: 生产环境使用 KEYS 命令需要非常小心。在大的数据库上执行命令会影响性能。
这个命令适合用来调试和特殊操作,像改变键空间布局。
不要在你的代码中使用 KEYS 。如果你需要一个寻找键空间中的key子集,考虑使用 SCAN 或 sets。
匹配模式:
- h?llo 匹配 hello, hallo 和 hxllo
- h*llo 匹配 hllo 和 heeeello
- h[ae]llo 匹配 hello and hallo, 不匹配 hillo
- h[^e]llo 匹配 hallo, hbllo, … 不匹配 hello
- h[a-b]llo 匹配 hallo 和 hbllo
使用 \ 转义你想匹配的特殊字符。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
192.168.3.204:7000> set hello hello
OK
192.168.3.204:7000> set hallo hallo
OK
192.168.3.204:7000> set hxllo hxllo
OK
192.168.3.204:7000> set hxxxlo hxxxlo
OK
192.168.3.204:7000> keys *
1) "hallo"
2) "myset"
3) "hello"
4) "hxllo"
5) "hxxxlo"
192.168.3.204:7000> keys h?llo
1) "hallo"
2) "hello"
3) "hxllo"
192.168.3.204:7000> keys h[ae]llo
1) "hallo"
2) "hello"
192.168.3.204:7000> keys h*lo
1) "hallo"
2) "hello"
3) "hxllo"
4) "hxxxlo"
192.168.3.204:7000> keys h[a-b]llo
1) "hallo"
|
del
DEL 命令用于删除给定的一个或多个 key 。不存在的 key 会被忽略。
1
2
3
4
5
6
7
|
192.168.3.204:7000> keys *
1) "myset"
2) "myfruits"
192.168.3.204:7000> del myfruits
(integer) 1
192.168.3.204:7000> keys *
1) "myset"
|
注意:不要在生产环境上使用keys *,会阻塞redis服务。
exists
EXISTS 命令用于检查给定 key 是否存在。
从 Redis 3.0.3 起可以一次检查多个 key 是否存在。这种情况下,返回待检查 key 中存在的 key 的个数。检查单个 key 返回 1 或 0 。
注意:如果相同的 key 在参数列表中出现了多次,它会被计算多次。所以,如果somekey存在, EXISTS somekey somekey 命令返回 2。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
192.168.3.204:7000> set key1 a
OK
192.168.3.204:7000> set key2 b
OK
192.168.3.204:7000> set key3 c
OK
192.168.3.204:7000> exists key1
(integer) 1
192.168.3.204:7000> exists key1 key2
(integer) 2
192.168.3.204:7000> exists nokey
(integer) 0
192.168.3.204:7000> exists key1 key2 key3 nokey
(integer) 3
|
所以,当检查N个key的时候,如果返回值为N,则表示所有key都存在,如果返回值为0,表示所有key都不存在。如果大于0且小于N,则表示有key不存在,但结果无法指明是哪个(些)key不存在。
expire / pexpire / pexireat / persist
Expire 命令设置 key 的过期时间(seconds)。 设置的时间过期后,key 会被自动删除。带有超时时间的 key 通常被称为易失的(volatile)。
EXPIREAT 与 EXPIRE 有相同的作用和语义, 不同的是 EXPIREAT 使用绝对 Unix 时间戳 (自1970年1月1日以来的秒数)代替表示过期时间的秒数。使用过去的时间戳将会立即删除该 key。
PEXPIRE 跟 EXPIRE 基本一样,只是过期时间单位是毫秒。
PERSIST 命令用于删除给定 key 的过期时间,使得 key 永不过期。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
192.168.3.204:7000> set hello test
OK
192.168.3.204:7000> ttl hello
(integer) -1
192.168.3.204:7000> expire hello 10
(integer) 1
192.168.3.204:7000> ttl hello
(integer) 7
192.168.3.204:7000> persist hello
(integer) 1
192.168.3.204:7000> ttl hello
(integer) -1
192.168.3.204:7000> expireat hello 1630801500
(integer) 1
192.168.3.204:7000> ttl hello
(integer) 90
|
ttl / pttl
TTL 命令以秒为单位返回 key 的剩余过期时间。用户客户端检查 key 还可以存在多久。Redis 2.6 之前的版本如果 key 不存在或者 key 没有关联超时时间则返回 -1 。
Redis 2.8 起:
- key 不存在返回
-2
- key 存在但是没有关联超时时间返回
-1
PTTL 返回以毫秒为单位的剩余超时时间。
1
2
3
4
5
6
7
8
9
10
11
12
|
192.168.3.204:7000> set hello test
OK
192.168.3.204:7000> ttl hello
(integer) -1
192.168.3.204:7000> expire hello 10
(integer) 1
192.168.3.204:7000> ttl hello
(integer) 7
192.168.3.204:7000> del hello
(integer) 1
192.168.3.204:7000> ttl hello
(integer) -2
|
move / migrate
MOVE 命令用于将当前数据库的 key 移动到选定的数据库 db 当中。
如果 key 在目标数据库中已存在,或者 key 在源数据库中不存,则key 不会被移动。如果 key 被移动了则返回1,否则返回0。
MIGRATE 将 key 原子性地从当前实例传送到目标实例的指定数据库上,一旦传送成功, key 会出现在目标实例上,而当前实例上的 key 会被删除。
MIGRATE 命令是一个原子操作,它在执行的时候会阻塞进行迁移的两个实例,直到以下任意结果发生:迁移成功,迁移失败,等待超时。
1
2
3
4
5
6
7
8
9
10
11
12
|
192.168.3.204:7000> select 0
OK
192.168.3.204:7000> set hello.db0 test
OK
192.168.3.204:7000> move hello.db0 1
(integer) 1
192.168.3.204:7000> select 1
OK
192.168.3.204:7000[1]> keys *
1) "hello.db0"
192.168.3.204:7000[1]> get hello.db0
"test"
|
scan
SCAN 命令及其相关命令 SSCAN, HSCAN ZSCAN 命令都是用于增量遍历集合中的元素。
- SCAN 命令用于迭代当前数据库中的数据库键
- SSCAN 命令用于迭代集合键中的元素。
- HSCAN 命令用于迭代哈希键中的键值对。
- ZSCAN 命令用于迭代有序集合中的元素(包括元素成员和元素分值)。
SCAN 命令基本语法如下:
1
|
SCAN cursor [MATCH pattern] [COUNT count]
|
- cursor - 游标。
- pattern - 匹配的模式。
- count - 指定从数据集里返回多少元素,默认值为 10 。
SCAN 命令是一个基于游标的迭代器,每次被调用之后, 都会向用户返回一个新的游标, 用户在下次迭代时需要使用这个新游标作为SCAN命令的游标参数, 以此来延续之前的迭代过程。
SCAN 返回一个包含两个元素的数组, 第一个元素是用于进行下一次迭代的新游标, 而第二个元素则是一个数组, 这个数组中包含了所有被迭代的元素。当 SCAN 命令的游标参数被设置为 0 时, 服务器将开始一次新的迭代,而当服务器向用户返回值为 0 的游标时, 表示迭代已结束。
为了测试scan命令,可以先在数据库中插入一批key和值,可以采用:
Redis从文件中批量插入数据(redis batch-insert) – Redis中国用户组(CRUG)
这篇文章所示的方法,批量执行文件中的命令。比如先通过下面的文件,批量插入200个key。
1
2
3
4
5
6
7
8
9
10
|
SET key001 val001
SET key002 val002
SET key003 val003
SET key004 val004
SET key005 val005
SET key006 val006
SET key007 val007
SET key008 val008
... // 省略
SET key200 val200
|
下面是一个使用scan遍历的例子:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
|
192.168.3.204:7000> scan 0 MATCH key*
1) "16"
2) 1) "key130"
2) "key018"
3) "key028"
4) "key048"
5) "key007"
6) "key088"
7) "key192"
8) "key181"
9) "key022"
10) "key104"
192.168.3.204:7000> scan 16 MATCH key*
1) "24"
2) 1) "key012"
2) "key132"
3) "key096"
4) "key134"
5) "key042"
6) "key083"
7) "key049"
8) "key065"
9) "key158"
10) "key038"
192.168.3.204:7000> scan 24 MATCH key*
1) "120"
2) 1) "key160"
2) "key153"
3) "key067"
4) "key190"
5) "key182"
6) "key010"
7) "key031"
8) "key147"
9) "key136"
10) "key121"
|
可以看到 scan 16 MATCH key* 和 scan 24 MATCH key* 都是使用上次返回的游标进行下一次的迭代。
SCAN命令可以保证:
- 如果有一个元素, 它从遍历开始直到遍历结束期间都存在于被遍历的数据集当中, 那么 SCAN 命令总会在某次迭代中将这个元素返回给用户。
- 如果有一个元素, 它从遍历开始就已经被删除,且直到遍历结束也没有被添加回来, 那么 SCAN 命令确保不会返回这个元素。
简言之就是:一直在的肯定会出现,一直不在的肯定不会出现。
然而因为 SCAN 命令仅仅使用游标来记录迭代状态, 所以这些命令带有以下缺点:
- 同一个元素可能会被返回多次。 处理重复元素的工作交由应用程序负责, 比如说, 可以考虑将迭代返回的元素仅仅用于可以安全地重复执行多次的操作上。
- 如果一个元素是在迭代过程中被添加到数据集的, 又或者是在迭代过程中从数据集中被删除的, 那么这个元素可能会被返回, 也可能不会, 这是未定义的(undefined)。
服务器相关
info
INFO命令以一种易于理解和阅读的格式,返回关于Redis服务器的各种信息和统计数值。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
|
192.168.3.204:7000> info
# Server
redis_version:4.0.11
redis_git_sha1:00000000
redis_git_dirty:0
redis_build_id:936dab87937e4629
redis_mode:standalone
os:Linux 3.4.79-r0-s-rm1+ armv7l
arch_bits:32
multiplexing_api:epoll
... // 很多其他信息,略
# Replication
role:master
connected_slaves:0
master_replid:9062b2ef8f36ed7b2ef30443e150997f9278bee6
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:0
second_repl_offset:-1
repl_backlog_active:0
repl_backlog_size:1048576
repl_backlog_first_byte_offset:0
repl_backlog_histlen:0
# CPU
used_cpu_sys:22.06
used_cpu_user:23.93
used_cpu_sys_children:0.00
used_cpu_user_children:0.00
# Cluster
cluster_enabled:0
# Keyspace
db0:keys=200,expires=0,avg_ttl=0
db1:keys=1,expires=0,avg_ttl=0
|
flushdb / flushall
flushdb 用于清空当前 select 数据库中的所有 key。此命令不会失败。
flushall 用于清空整个 Redis 服务器的数据(删除所有数据库的所有 key,不仅仅是当前 select 数据库 )。此命令不会失败。时间复杂度是 O(N), N 代表所有数据库中 key 的总数。
1
2
3
4
5
6
|
192.168.3.204:7000> dbsize
(integer) 200
192.168.3.204:7000> flushdb
OK
192.168.3.204:7000> dbsize
(integer) 0
|
注意:这是两个十分危险的命令,一般在生产环境上是不会使用的,就算要使用,也会通过将命令重命名的方式,避免误操作。
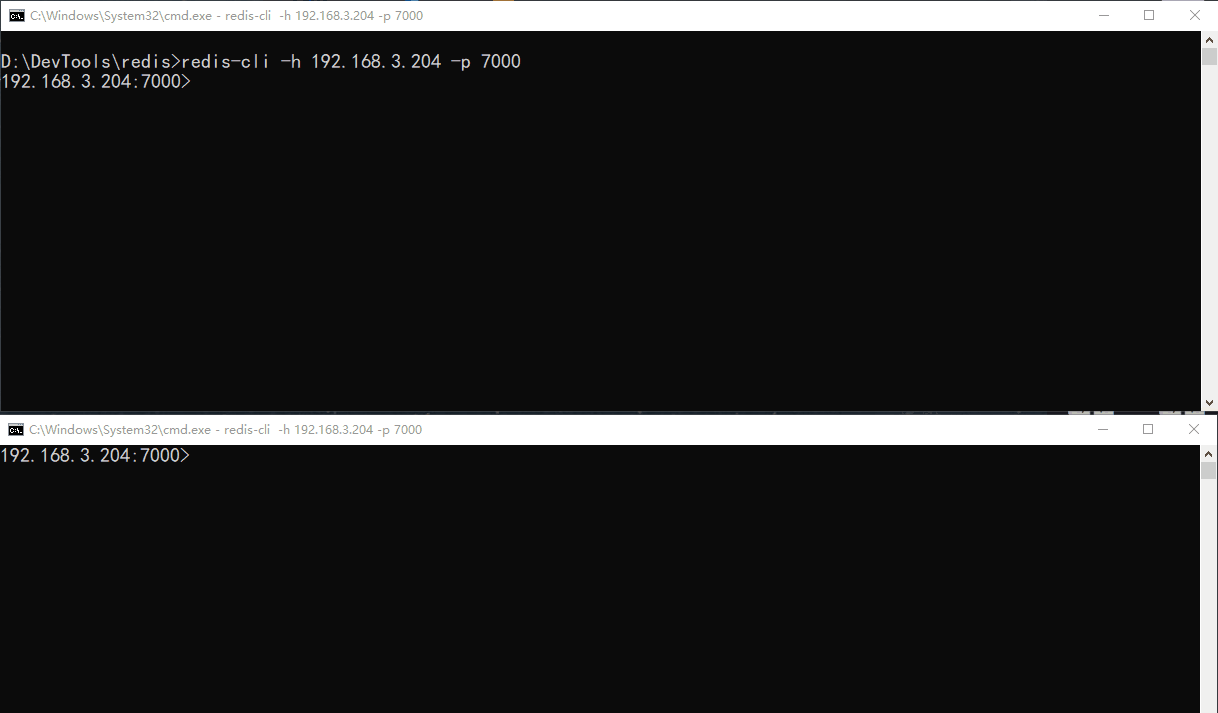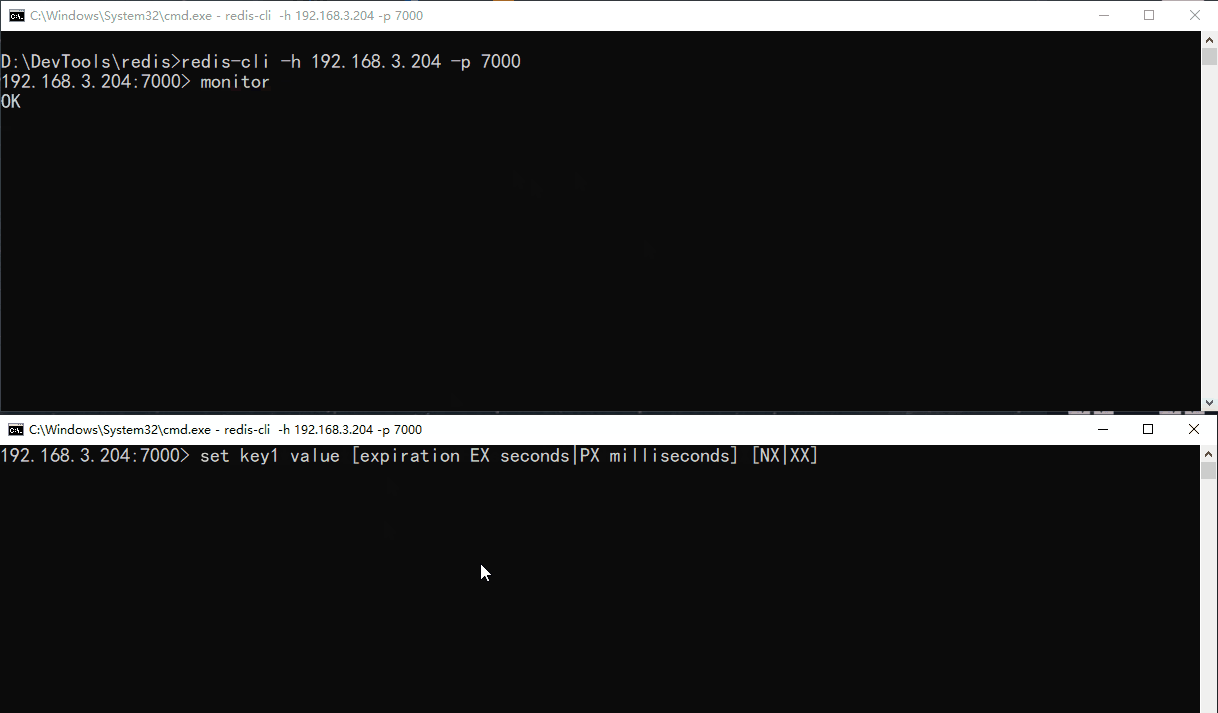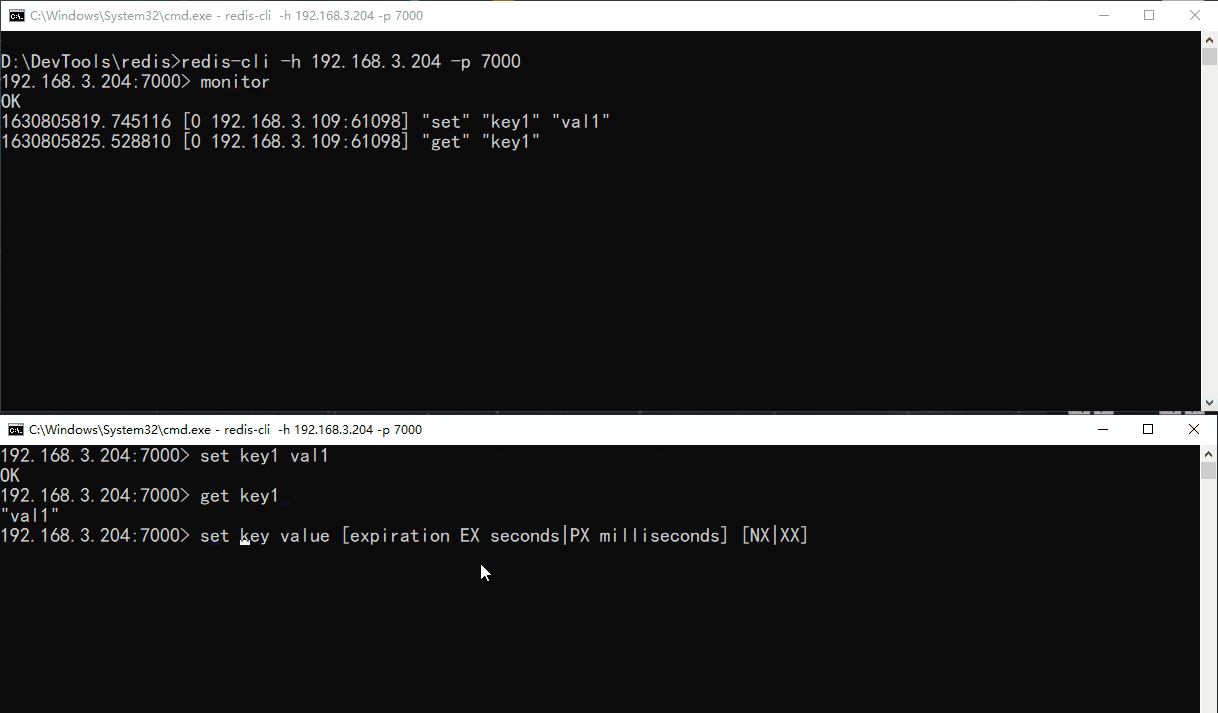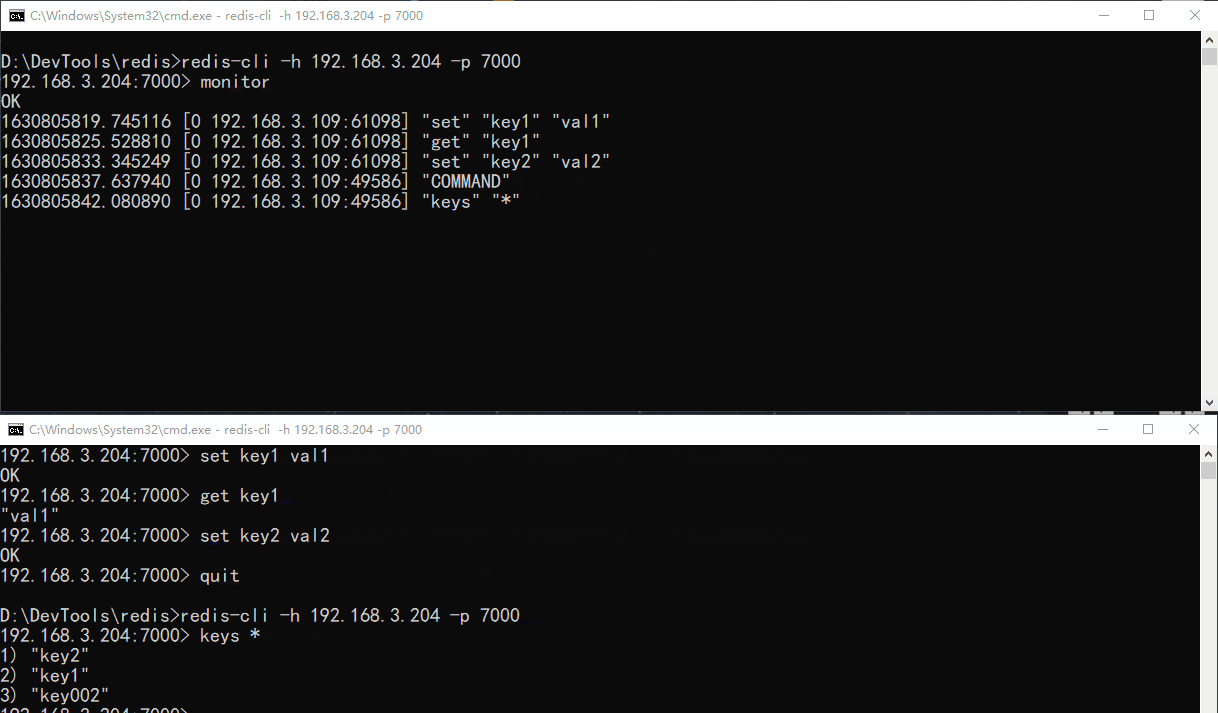
monitor
MONITOR 命令用于实时打印出 Redis 服务器接收到的命令,调试用。
MONITOR 用来帮助我们知道数库正在做什么。可以通过 redis-cli 和 telnet 调用 MONITOR。
Redis详细命令:Redis命令中心(Redis commands) – Redis中国用户组(CRUG)
Redis配置文件
Reids配置文件说明,redis版本为(3.2)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
|
#redis.conf
# Redis configuration file example.
# ./redis-server /path/to/redis.conf
################################## INCLUDES ###################################
#这在你有标准配置模板但是每个redis服务器又需要个性设置的时候很有用。
# include /path/to/local.conf
# include /path/to/other.conf
################################ GENERAL #####################################
#是否在后台执行,yes:后台运行;no:不是后台运行(老版本默认)
daemonize yes
#3.2里的参数,是否开启保护模式,默认开启。要是配置里没有指定bind和密码。开启该参数后,redis只会本地进行访问,拒绝外部访问。要是开启了密码 和bind,可以开启。否则最好关闭,设置为no。
protected-mode yes
#redis的进程文件
pidfile /var/run/redis/redis-server.pid
#redis监听的端口号。
port 6379
#此参数确定了TCP连接中已完成队列(完成三次握手之后)的长度, 当然此值必须不大于Linux系统定义的/proc/sys/net/core/somaxconn值,默认是511,而Linux的默认参数值是128。当系统并发量大并且客户端速度缓慢的时候,可以将这二个参数一起参考设定。该内核参数默认值一般是128,对于负载很大的服务程序来说大大的不够。一般会将它修改为2048或者更大。在/etc/sysctl.conf中添加:net.core.somaxconn = 2048,然后在终端中执行sysctl -p。
tcp-backlog 511
#指定 redis 只接收来自于该 IP 地址的请求,如果不进行设置,那么将处理所有请求
bind 127.0.0.1
#配置unix socket来让redis支持监听本地连接。
# unixsocket /var/run/redis/redis.sock
#配置unix socket使用文件的权限
# unixsocketperm 700
# 此参数为设置客户端空闲超过timeout,服务端会断开连接,为0则服务端不会主动断开连接,不能小于0。
timeout 0
#tcp keepalive参数。如果设置不为0,就使用配置tcp的SO_KEEPALIVE值,使用keepalive有两个好处:检测挂掉的对端。降低中间设备出问题而导致网络看似连接却已经与对端端口的问题。在Linux内核中,设置了keepalive,redis会定时给对端发送ack。检测到对端关闭需要两倍的设置值。
tcp-keepalive 0
#指定了服务端日志的级别。级别包括:debug(很多信息,方便开发、测试),verbose(许多有用的信息,但是没有debug级别信息多),notice(适当的日志级别,适合生产环境),warn(只有非常重要的信息)
loglevel notice
#指定了记录日志的文件。空字符串的话,日志会打印到标准输出设备。后台运行的redis标准输出是/dev/null。
logfile /var/log/redis/redis-server.log
#是否打开记录syslog功能
# syslog-enabled no
#syslog的标识符。
# syslog-ident redis
#日志的来源、设备
# syslog-facility local0
#数据库的数量,默认使用的数据库是DB 0。可以通过”SELECT “命令选择一个db
databases 16
################################ SNAPSHOTTING ################################
# 快照配置
# 注释掉“save”这一行配置项就可以让保存数据库功能失效
# 设置sedis进行数据库镜像的频率。
# 900秒(15分钟)内至少1个key值改变(则进行数据库保存--持久化)
# 300秒(5分钟)内至少10个key值改变(则进行数据库保存--持久化)
# 60秒(1分钟)内至少10000个key值改变(则进行数据库保存--持久化)
save 900 1
save 300 10
save 60 10000
#当RDB持久化出现错误后,是否依然进行继续进行工作,yes:不能进行工作,no:可以继续进行工作,可以通过info中的rdb_last_bgsave_status了解RDB持久化是否有错误
stop-writes-on-bgsave-error yes
#使用压缩rdb文件,rdb文件压缩使用LZF压缩算法,yes:压缩,但是需要一些cpu的消耗。no:不压缩,需要更多的磁盘空间
rdbcompression yes
#是否校验rdb文件。从rdb格式的第五个版本开始,在rdb文件的末尾会带上CRC64的校验和。这跟有利于文件的容错性,但是在保存rdb文件的时候,会有大概10%的性能损耗,所以如果你追求高性能,可以关闭该配置。
rdbchecksum yes
#rdb文件的名称
dbfilename dump.rdb
#数据目录,数据库的写入会在这个目录。rdb、aof文件也会写在这个目录
dir /var/lib/redis
################################# REPLICATION #################################
#复制选项,slave复制对应的master。
# slaveof <masterip> <masterport>
#如果master设置了requirepass,那么slave要连上master,需要有master的密码才行。masterauth就是用来配置master的密码,这样可以在连上master后进行认证。
# masterauth <master-password>
#当从库同主机失去连接或者复制正在进行,从机库有两种运行方式:1) 如果slave-serve-stale-data设置为yes(默认设置),从库会继续响应客户端的请求。2) 如果slave-serve-stale-data设置为no,除去INFO和SLAVOF命令之外的任何请求都会返回一个错误”SYNC with master in progress”。
slave-serve-stale-data yes
#作为从服务器,默认情况下是只读的(yes),可以修改成NO,用于写(不建议)。
slave-read-only yes
#是否使用socket方式复制数据。目前redis复制提供两种方式,disk和socket。如果新的slave连上来或者重连的slave无法部分同步,就会执行全量同步,master会生成rdb文件。有2种方式:disk方式是master创建一个新的进程把rdb文件保存到磁盘,再把磁盘上的rdb文件传递给slave。socket是master创建一个新的进程,直接把rdb文件以socket的方式发给slave。disk方式的时候,当一个rdb保存的过程中,多个slave都能共享这个rdb文件。socket的方式就的一个个slave顺序复制。在磁盘速度缓慢,网速快的情况下推荐用socket方式。
repl-diskless-sync no
#diskless复制的延迟时间,防止设置为0。一旦复制开始,节点不会再接收新slave的复制请求直到下一个rdb传输。所以最好等待一段时间,等更多的slave连上来。
repl-diskless-sync-delay 5
#slave根据指定的时间间隔向服务器发送ping请求。时间间隔可以通过 repl_ping_slave_period 来设置,默认10秒。
# repl-ping-slave-period 10
#复制连接超时时间。master和slave都有超时时间的设置。master检测到slave上次发送的时间超过repl-timeout,即认为slave离线,清除该slave信息。slave检测到上次和master交互的时间超过repl-timeout,则认为master离线。需要注意的是repl-timeout需要设置一个比repl-ping-slave-period更大的值,不然会经常检测到超时。
# repl-timeout 60
#是否禁止复制tcp链接的tcp nodelay参数,可传递yes或者no。默认是no,即使用tcp nodelay。如果master设置了yes来禁止tcp nodelay设置,在把数据复制给slave的时候,会减少包的数量和更小的网络带宽。但是这也可能带来数据的延迟。默认我们推荐更小的延迟,但是在数据量传输很大的场景下,建议选择yes。
repl-disable-tcp-nodelay no
#复制缓冲区大小,这是一个环形复制缓冲区,用来保存最新复制的命令。这样在slave离线的时候,不需要完全复制master的数据,如果可以执行部分同步,只需要把缓冲区的部分数据复制给slave,就能恢复正常复制状态。缓冲区的大小越大,slave离线的时间可以更长,复制缓冲区只有在有slave连接的时候才分配内存。没有slave的一段时间,内存会被释放出来,默认1m。
# repl-backlog-size 5mb
#master没有slave一段时间会释放复制缓冲区的内存,repl-backlog-ttl用来设置该时间长度。单位为秒。
# repl-backlog-ttl 3600
#当master不可用,Sentinel会根据slave的优先级选举一个master。最低的优先级的slave,当选master。而配置成0,永远不会被选举。
slave-priority 100
#redis提供了可以让master停止写入的方式,如果配置了min-slaves-to-write,健康的slave的个数小于N,mater就禁止写入。master最少得有多少个健康的slave存活才能执行写命令。这个配置虽然不能保证N个slave都一定能接收到master的写操作,但是能避免没有足够健康的slave的时候,master不能写入来避免数据丢失。设置为0是关闭该功能。
# min-slaves-to-write 3
#延迟小于min-slaves-max-lag秒的slave才认为是健康的slave。
# min-slaves-max-lag 10
# 设置1或另一个设置为0禁用这个特性。
# Setting one or the other to 0 disables the feature.
# By default min-slaves-to-write is set to 0 (feature disabled) and
# min-slaves-max-lag is set to 10.
################################## SECURITY ###################################
#requirepass配置可以让用户使用AUTH命令来认证密码,才能使用其他命令。这让redis可以使用在不受信任的网络中。为了保持向后的兼容性,可以注释该命令,因为大部分用户也不需要认证。使用requirepass的时候需要注意,因为redis太快了,每秒可以认证15w次密码,简单的密码很容易被攻破,所以最好使用一个更复杂的密码。
# requirepass foobared
#把危险的命令给修改成其他名称。比如CONFIG命令可以重命名为一个很难被猜到的命令,这样用户不能使用,而内部工具还能接着使用。
# rename-command CONFIG b840fc02d524045429941cc15f59e41cb7be6c52
#设置成一个空的值,可以禁止一个命令
# rename-command CONFIG ""
################################### LIMITS ####################################
# 设置能连上redis的最大客户端连接数量。默认是10000个客户端连接。由于redis不区分连接是客户端连接还是内部打开文件或者和slave连接等,所以maxclients最小建议设置到32。如果超过了maxclients,redis会给新的连接发送’max number of clients reached’,并关闭连接。
# maxclients 10000
#redis配置的最大内存容量。当内存满了,需要配合maxmemory-policy策略进行处理。注意slave的输出缓冲区是不计算在maxmemory内的。所以为了防止主机内存使用完,建议设置的maxmemory需要更小一些。
# maxmemory <bytes>
#内存容量超过maxmemory后的处理策略。
#volatile-lru:利用LRU算法移除设置过过期时间的key。
#volatile-random:随机移除设置过过期时间的key。
#volatile-ttl:移除即将过期的key,根据最近过期时间来删除(辅以TTL)
#allkeys-lru:利用LRU算法移除任何key。
#allkeys-random:随机移除任何key。
#noeviction:不移除任何key,只是返回一个写错误。
#上面的这些驱逐策略,如果redis没有合适的key驱逐,对于写命令,还是会返回错误。redis将不再接收写请求,只接收get请求。写命令包括:set setnx setex append incr decr rpush lpush rpushx lpushx linsert lset rpoplpush sadd sinter sinterstore sunion sunionstore sdiff sdiffstore zadd zincrby zunionstore zinterstore hset hsetnx hmset hincrby incrby decrby getset mset msetnx exec sort。
# maxmemory-policy noeviction
#lru检测的样本数。使用lru或者ttl淘汰算法,从需要淘汰的列表中随机选择sample个key,选出闲置时间最长的key移除。
# maxmemory-samples 5
############################## APPEND ONLY MODE ###############################
#默认redis使用的是rdb方式持久化,这种方式在许多应用中已经足够用了。但是redis如果中途宕机,会导致可能有几分钟的数据丢失,根据save来策略进行持久化,Append Only File是另一种持久化方式,可以提供更好的持久化特性。Redis会把每次写入的数据在接收后都写入 appendonly.aof 文件,每次启动时Redis都会先把这个文件的数据读入内存里,先忽略RDB文件。
appendonly no
#aof文件名
appendfilename "appendonly.aof"
#aof持久化策略的配置
#no表示不执行fsync,由操作系统保证数据同步到磁盘,速度最快。
#always表示每次写入都执行fsync,以保证数据同步到磁盘。
#everysec表示每秒执行一次fsync,可能会导致丢失这1s数据。
appendfsync everysec
# 在aof重写或者写入rdb文件的时候,会执行大量IO,此时对于everysec和always的aof模式来说,执行fsync会造成阻塞过长时间,no-appendfsync-on-rewrite字段设置为默认设置为no。如果对延迟要求很高的应用,这个字段可以设置为yes,否则还是设置为no,这样对持久化特性来说这是更安全的选择。设置为yes表示rewrite期间对新写操作不fsync,暂时存在内存中,等rewrite完成后再写入,默认为no,建议yes。Linux的默认fsync策略是30秒。可能丢失30秒数据。
no-appendfsync-on-rewrite no
#aof自动重写配置。当目前aof文件大小超过上一次重写的aof文件大小的百分之多少进行重写,即当aof文件增长到一定大小的时候Redis能够调用bgrewriteaof对日志文件进行重写。当前AOF文件大小是上次日志重写得到AOF文件大小的二倍(设置为100)时,自动启动新的日志重写过程。
auto-aof-rewrite-percentage 100
#设置允许重写的最小aof文件大小,避免了达到约定百分比但尺寸仍然很小的情况还要重写
auto-aof-rewrite-min-size 64mb
#aof文件可能在尾部是不完整的,当redis启动的时候,aof文件的数据被载入内存。重启可能发生在redis所在的主机操作系统宕机后,尤其在ext4文件系统没有加上data=ordered选项(redis宕机或者异常终止不会造成尾部不完整现象。)出现这种现象,可以选择让redis退出,或者导入尽可能多的数据。如果选择的是yes,当截断的aof文件被导入的时候,会自动发布一个log给客户端然后load。如果是no,用户必须手动redis-check-aof修复AOF文件才可以。
aof-load-truncated yes
################################ LUA SCRIPTING ###############################
# 如果达到最大时间限制(毫秒),redis会记个log,然后返回error。当一个脚本超过了最大时限。只有SCRIPT KILL和SHUTDOWN NOSAVE可以用。第一个可以杀没有调write命令的东西。要是已经调用了write,只能用第二个命令杀。
lua-time-limit 5000
################################ REDIS CLUSTER ###############################
#集群开关,默认是不开启集群模式。
# cluster-enabled yes
#集群配置文件的名称,每个节点都有一个集群相关的配置文件,持久化保存集群的信息。这个文件并不需要手动配置,这个配置文件有Redis生成并更新,每个Redis集群节点需要一个单独的配置文件,请确保与实例运行的系统中配置文件名称不冲突
# cluster-config-file nodes-6379.conf
#节点互连超时的阀值。集群节点超时毫秒数
# cluster-node-timeout 15000
#在进行故障转移的时候,全部slave都会请求申请为master,但是有些slave可能与master断开连接一段时间了,导致数据过于陈旧,这样的slave不应该被提升为master。该参数就是用来判断slave节点与master断线的时间是否过长。判断方法是:
#比较slave断开连接的时间和(node-timeout * slave-validity-factor) + repl-ping-slave-period
#如果节点超时时间为三十秒, 并且slave-validity-factor为10,假设默认的repl-ping-slave-period是10秒,即如果超过310秒slave将不会尝试进行故障转移
# cluster-slave-validity-factor 10
#master的slave数量大于该值,slave才能迁移到其他孤立master上,如这个参数若被设为2,那么只有当一个主节点拥有2 个可工作的从节点时,它的一个从节点会尝试迁移。
# cluster-migration-barrier 1
#默认情况下,集群全部的slot有节点负责,集群状态才为ok,才能提供服务。设置为no,可以在slot没有全部分配的时候提供服务。不建议打开该配置,这样会造成分区的时候,小分区的master一直在接受写请求,而造成很长时间数据不一致。
# cluster-require-full-coverage yes
################################## SLOW LOG ###################################
###slog log是用来记录redis运行中执行比较慢的命令耗时。当命令的执行超过了指定时间,就记录在slow log中,slog log保存在内存中,所以没有IO操作。
#执行时间比slowlog-log-slower-than大的请求记录到slowlog里面,单位是微秒,所以1000000就是1秒。注意,负数时间会禁用慢查询日志,而0则会强制记录所有命令。
slowlog-log-slower-than 10000
#慢查询日志长度。当一个新的命令被写进日志的时候,最老的那个记录会被删掉。这个长度没有限制。只要有足够的内存就行。你可以通过 SLOWLOG RESET 来释放内存。
slowlog-max-len 128
################################ LATENCY MONITOR ##############################
#延迟监控功能是用来监控redis中执行比较缓慢的一些操作,用LATENCY打印redis实例在跑命令时的耗时图表。只记录大于等于下边设置的值的操作。0的话,就是关闭监视。默认延迟监控功能是关闭的,如果你需要打开,也可以通过CONFIG SET命令动态设置。
latency-monitor-threshold 0
############################# EVENT NOTIFICATION ##############################
#键空间通知使得客户端可以通过订阅频道或模式,来接收那些以某种方式改动了 Redis 数据集的事件。因为开启键空间通知功能需要消耗一些 CPU ,所以在默认配置下,该功能处于关闭状态。
#notify-keyspace-events 的参数可以是以下字符的任意组合,它指定了服务器该发送哪些类型的通知:
##K 键空间通知,所有通知以 __keyspace@__ 为前缀
##E 键事件通知,所有通知以 __keyevent@__ 为前缀
##g DEL 、 EXPIRE 、 RENAME 等类型无关的通用命令的通知
##$ 字符串命令的通知
##l 列表命令的通知
##s 集合命令的通知
##h 哈希命令的通知
##z 有序集合命令的通知
##x 过期事件:每当有过期键被删除时发送
##e 驱逐(evict)事件:每当有键因为 maxmemory 政策而被删除时发送
##A 参数 g$lshzxe 的别名
#输入的参数中至少要有一个 K 或者 E,否则的话,不管其余的参数是什么,都不会有任何 通知被分发。详细使用可以参考http://redis.io/topics/notifications
notify-keyspace-events ""
############################### ADVANCED CONFIG ###############################
#数据量小于等于hash-max-ziplist-entries的用ziplist,大于hash-max-ziplist-entries用hash
hash-max-ziplist-entries 512
#value大小小于等于hash-max-ziplist-value的用ziplist,大于hash-max-ziplist-value用hash。
hash-max-ziplist-value 64
#数据量小于等于list-max-ziplist-entries用ziplist,大于list-max-ziplist-entries用list。
list-max-ziplist-entries 512
#value大小小于等于list-max-ziplist-value的用ziplist,大于list-max-ziplist-value用list。
list-max-ziplist-value 64
#数据量小于等于set-max-intset-entries用iniset,大于set-max-intset-entries用set。
set-max-intset-entries 512
#数据量小于等于zset-max-ziplist-entries用ziplist,大于zset-max-ziplist-entries用zset。
zset-max-ziplist-entries 128
#value大小小于等于zset-max-ziplist-value用ziplist,大于zset-max-ziplist-value用zset。
zset-max-ziplist-value 64
#value大小小于等于hll-sparse-max-bytes使用稀疏数据结构(sparse),大于hll-sparse-max-bytes使用稠密的数据结构(dense)。一个比16000大的value是几乎没用的,建议的value大概为3000。如果对CPU要求不高,对空间要求较高的,建议设置到10000左右。
hll-sparse-max-bytes 3000
#Redis将在每100毫秒时使用1毫秒的CPU时间来对redis的hash表进行重新hash,可以降低内存的使用。当你的使用场景中,有非常严格的实时性需要,不能够接受Redis时不时的对请求有2毫秒的延迟的话,把这项配置为no。如果没有这么严格的实时性要求,可以设置为yes,以便能够尽可能快的释放内存。
activerehashing yes
##对客户端输出缓冲进行限制可以强迫那些不从服务器读取数据的客户端断开连接,用来强制关闭传输缓慢的客户端。
#对于normal client,第一个0表示取消hard limit,第二个0和第三个0表示取消soft limit,normal client默认取消限制,因为如果没有寻问,他们是不会接收数据的。
client-output-buffer-limit normal 0 0 0
#对于slave client和MONITER client,如果client-output-buffer一旦超过256mb,又或者超过64mb持续60秒,那么服务器就会立即断开客户端连接。
client-output-buffer-limit slave 256mb 64mb 60
#对于pubsub client,如果client-output-buffer一旦超过32mb,又或者超过8mb持续60秒,那么服务器就会立即断开客户端连接。
client-output-buffer-limit pubsub 32mb 8mb 60
#redis执行任务的频率为1s除以hz。
hz 10
#在aof重写的时候,如果打开了aof-rewrite-incremental-fsync开关,系统会每32MB执行一次fsync。这对于把文件写入磁盘是有帮助的,可以避免过大的延迟峰值。
aof-rewrite-incremental-fsync yes
|
Redis缓存常见问题
缓存雪崩
当某一个时刻出现大规模的缓存失效的情况,那么就会导致大量的请求直接打在数据库上面,导致数据库压力巨大,如果在高并发的情况下,可能瞬间就会导致数据库宕机。这时候如果运维马上又重启数据库,马上又会有新的流量把数据库打死。这就是缓存雪崩。
造成缓存雪崩的关键在于在同一时间大规模的key失效。为什么会出现这个问题呢,有几种可能,第一种可能是Redis宕机,第二种可能是采用了相同的过期时间。搞清楚原因之后,那么有什么解决方案呢?
解决方案
- 在原有的失效时间上加上一个随机值,比如1-5分钟随机。这样就避免了因为采用相同的过期时间导致的缓存雪崩。
如果真的发生了缓存雪崩,有没有什么兜底的措施?
-
使用熔断机制。当流量到达一定的阈值时,就直接返回“系统拥挤”之类的提示,防止过多的请求打在数据库上。至少能保证一部分用户是可以正常使用,其他用户多刷新几次也能得到结果。
-
提高数据库的容灾能力,可以使用分库分表,读写分离的策略。
-
为了防止Redis宕机导致缓存雪崩的问题,可以搭建Redis集群,提高Redis的容灾性。
缓存击穿
其实跟缓存雪崩有点类似,缓存雪崩是大规模的key失效,而缓存击穿是一个热点的Key,有大并发集中对其进行访问,突然间这个Key失效了,导致大并发全部打在数据库上,导致数据库压力剧增。这种现象就叫做缓存击穿。
关键在于某个热点的key失效了,导致大并发集中打在数据库上。所以要从两个方面解决,第一是否可以考虑热点key不设置过期时间,第二是否可以考虑降低打在数据库上的请求数量。
解决方案
缓存穿透
我们使用Redis大部分情况都是通过Key查询对应的值,假如发送的请求传进来的key是不存在Redis中的,那么就查不到缓存,查不到缓存就会去数据库查询。假如有大量这样的请求,这些请求像“穿透”了缓存一样直接打在数据库上,这种现象就叫做缓存穿透。
关键在于在Redis查不到key值,这和缓存击穿有根本的区别,区别在于缓存穿透的情况是传进来的key在Redis中是不存在的。假如有黑客传进大量的不存在的key,那么大量的请求打在数据库上是很致命的问题,所以在日常开发中要对参数做好校验,一些非法的参数,不可能存在的key就直接返回错误提示,要对调用方保持这种“不信任”的心态。

解决方案
-
**把无效的Key存进Redis中。**如果Redis查不到数据,数据库也查不到,我们把这个Key值保存进Redis,设置value=“null”,当下次再通过这个Key查询时就不需要再查询数据库。这种处理方式肯定是有问题的,假如传进来的这个不存在的Key值每次都是随机的,那存进Redis也没有意义。
-
使用布隆过滤器。布隆过滤器的作用是某个key不存在,那么就一定不存在,它说某个key存在,那么很大可能是存在(存在一定的误判率)。于是我们可以在缓存之前再加一层布隆过滤器,在查询的时候先去布隆过滤器查询key是否存在,如果不存在就直接返回。

双写一致性
只要使用缓存,就可能会涉及到缓存与数据库双存储双写;只要是双写,就一定会有数据一致性的问题,那么如何解决一致性问题?
一般来说,如果允许缓存可以稍微的跟数据库偶尔有不一致的情况,也就是说如果你的系统不是严格要求“缓存+数据库”必须保持一致性的话,最好不要做这个方案,即:读请求和写请求串行化,串到一个内存队列里去。串行化可以保证一定不会出现不一致的情况,但是它也会导致系统的吞吐量大幅度降低,用比正常情况下多几倍的机器去支撑线上的一个请求。
Cache Aside Pattern
最经典的缓存+数据库读写的模式,就是 Cache Aside Pattern。
- 读的时候,先读缓存,缓存没有的话,就读数据库,然后取出数据后放入缓存,同时返回响应。
- 更新的时候,先更新数据库,然后再删除缓存。
其实也就是,只要更新了数据,就把缓存给删除掉。
复杂的数据不一致问题
数据发生了变更,先删除了缓存,然后要去修改数据库,此时还没修改。一个请求过来,去读缓存,发现缓存空了,去查询数据库,查到了修改前的旧数据,放到了缓存中。随后数据变更的程序完成了数据库的修改。完了,数据库和缓存中的数据不一样了。
只有在对一个数据在并发的进行读写的时候,才可能会出现这种问题。其实如果说你的并发量很低的话,特别是读并发很低,每天访问量就1万次,那么很少的情况下,会出现刚才描述的那种不一致的场景。但是问题是,如果每天的是上亿的流量,每秒并发读是几万,每秒只要有数据更新的请求,就可能会出现上述的数据库+缓存不一致的情况。
解决方案如下
更新数据的时候,根据数据的唯一标识,将操作路由之后,发送到一个jvm内部队列中。读取数据的时候,如果发现数据不在缓存中,那么将重新读取数据+更新缓存的操作,根据唯一标识路由之后,也发送同一个jvm 内部队列中。
一个队列对应一个工作线程,每个工作线程串行拿到对应的操作,然后一条一条的执行。这样的话一个数据变更的操作,先删除缓存,然后再去更新数据库,但是还没完成更新。此时如果一个读请求过来,没有读到缓存,那么可以先将缓存更新的请求发送到队列中,此时会在队列中积压,然后同步等待缓存更新完成。
这里有一个优化点,一个队列中,其实多个更新缓存请求串在一起是没意义的,因此可以做过滤,如果发现队列中已经有一个更新缓存的请求了,那么就不用再放个更新请求操作进去了,直接等待前面的更新操作请求完成即可。
待那个队列对应的工作线程完成了上一个操作的数据库的修改之后,才会去执行下一个操作,也就是缓存更新的操作,此时会从数据库中读取最新的值,然后写入缓存中。
如果请求还在等待时间范围内,不断轮询发现可以取到值了,那么就直接返回;如果请求等待的时间超过一定时长,那么这一次直接从数据库中读取当前的旧值。
Redis持久化
bgsave做镜像全量持久化,aof做增量持久化。因为bgsave会耗费较长时间,不够实时,在停机的时候会导致大量丢失数据,所以需要aof来配合使用。在redis实例重启时,优先使用aof来恢复内存的状态,如果没有aof日志,就会使用rdb文件来恢复。
如果再问aof文件过大恢复时间过长怎么办?你告诉面试官,Redis会定期做aof重写,压缩aof文件日志大小。如果面试官不够满意,再拿出杀手锏答案,Redis4.0之后有了混合持久化的功能,将bgsave的全量和aof的增量做了融合处理,这样既保证了恢复的效率又兼顾了数据的安全性。这个功能甚至很多面试官都不知道,他们肯定会对你刮目相看。
如果对方追问那如果突然机器掉电会怎样?取决于aof日志sync属性的配置,如果不要求性能,在每条写指令时都sync一下磁盘,就不会丢失数据。但是在高性能的要求下每次都sync是不现实的,一般都使用定时sync,比如1s1次,这个时候最多就会丢失1s的数据。
====
持久化主要是做灾难恢复、数据恢复,也可以归类到高可用的一个环节中去,比如你redis整个挂了,然后redis就不可用了,你要做的事情就是让redis变得可用,尽快变得可用。
重启redis,尽快让它对外提供服务,如果没做数据备份,这时候redis启动了,也不可用啊,数据都没了。
很可能说,大量的请求过来,缓存全部无法命中,在redis里根本找不到数据,这个时候就死定了,出现缓存击穿问题。所有请求没有在redis命中,就会去mysql数据库这种数据源头中去找,一下子mysql承接高并发,然后就挂了…
如果你把redis持久化做好,备份和恢复方案做到企业级的程度,那么即使你的redis故障了,也可以通过备份数据,快速恢复,一旦恢复立即对外提供服务。
redis 持久化的两种方式
通过 RDB 或 AOF,都可以将redis内存中的数据给持久化到磁盘上面来,然后可以将这些数据备份到别的地方去,比如说阿里云等云服务。
如果redis挂了,服务器上的内存和磁盘上的数据都丢了,可以从云服务上拷贝回来之前的数据,放到指定的目录中,然后重新启动 redis,redis 就会自动根据持久化数据文件中的数据,去恢复内存中的数据,继续对外提供服务。
如果同时使用 RDB 和 AOF两种持久化机制,那么在redis重启的时候,会使用 AOF来重新构建数据,因为 AOF中的数据更加完整。
RDB 优缺点
- RDB会生成多个数据文件,每个数据文件都代表了某一个时刻中redis的数据,这种多个数据文件的方式,非常适合做冷备,可以将这种完整的数据文件发送到一些远程的安全存储上去,比如说Amazon的S3云服务上去,在国内可以是阿里云的 ODPS分布式存储上,以预定好的备份策略来定期备份redis中的数据。
- RDB 对redis对外提供的读写服务,影响非常小,可以让redis保持高性能,因为redis主进程只需要 fork一个子进程,让子进程执行磁盘 IO 操作来进行 RDB 持久化即可。
- 相对于 AOF持久化机制来说,直接基于 RDB 数据文件来重启和恢复redis进程,更加快速。
- 如果想要在redis故障时,尽可能少的丢失数据,那么 RDB 没有 AOF好。一般来说,RDB 数据快照文件,都是每隔 5 分钟,或者更长时间生成一次,这个时候就得接受一旦redis进程宕机,那么会丢失最近 5 分钟的数据。
- RDB 每次在 fork 子进程来执行 RDB 快照数据文件生成的时候,如果数据文件特别大,可能会导致对客户端提供的服务暂停数毫秒,或者甚至数秒。
AOF优缺点
- AOF可以更好的保护数据不丢失,一般 AOF会每隔 1 秒,通过一个后台线程执行一次 fsync 操作,最多丢失 1 秒钟的数据。
- AOF日志文件以 append-only 模式写入,所以没有任何磁盘寻址的开销,写入性能非常高,而且文件不容易破损,即使文件尾部破损,也很容易修复。
- AOF日志文件即使过大的时候,出现后台重写操作,也不会影响客户端的读写。因为在 rewrite log的时候,会对其中的指令进行压缩,创建出一份需要恢复数据的最小日志出来。在创建新日志文件的时候,老的日志文件还是照常写入。当新的merge后日志文件ready的时候,在交换新老日志文件即可。
- AOF日志文件的命令通过非常可读的方式进行记录,这个特性非常适合做灾难性的误删除的紧急恢复。比如某人不小心用 flushall 命令清空了所有数据,只要这个时候后台 rewrite 还没有发生,那么就可以立即拷贝 AOF文件,将最后一条 flushall 命令给删了,然后再将该 AOF文件放回去,就可以通过恢复机制,自动恢复所有数据。
- 对于同一份数据来说,AOF日志文件通常比 RDB 数据快照文件更大。
- AOF开启后,支持的写 QPS 会比 RDB 支持的写 QPS 低,因为 AOF一般会配置成每秒 fsync 一次日志文件,当然,每秒一次 fsync,性能也还是很高的。(如果实时写入,那么 QPS 会大降,redis 性 能会大大降低)
- 以前 AOF发生过 bug,就是通过 AOF记录的日志,进行数据恢复的时候,没有恢复一模一样的数据出来。所以说,类似 AOF这种较为复杂的基于命令日志 / merge / 回放的方式,比基于 RDB 每次持久化一份完整的数据快照文件的方式,更加脆弱一些,容易有 bug。不过 AOF就是为了避免 rewrite 过程导致的 bug,因此每次 rewrite 并不是基于旧的指令日志进行 merge 的,而是基于当时内存中的数据进行指令的重新构建,这样健壮性会好很多。
RDB 和AOF到底该如何选择
一般来说,如果想达到足以媲美 PostgreSQL 的数据安全性, 你应该同时使用两种持久化功能。
如果你非常关心你的数据,但仍然可以承受数分钟以内的数据丢失, 那么你可以只使用 RDB 持久化。
有很多用户单独使用AOF,但是我们并不鼓励这样,因为时常进行RDB快照非常方便于数据库备份,启动速度也较之快,还避免了AOF引擎的bug。
注意:基于这些原因,将来Redis官方可能会统一AOF和RDB为一种单一的持久化模型(长远计划)。
快照的运作方式:
当 Redis 需要保存 dump.rdb 文件时, 服务器执行以下操作:
- Redis 调用 fork() ,同时拥有父进程和子进程。
- 子进程将数据集写入到一个临时 RDB 文件中。
- 当子进程完成对新 RDB 文件的写入时,Redis 用新 RDB 文件替换原来的 RDB 文件,并删除旧的 RDB 文件。
这种工作方式使得 Redis 可以从写时复制(copy-on-write)机制中获益。
Redis过期策略
常见的有两个问题:
1)往redis写入的数据怎么没了?
可能有同学会遇到,在生产环境的redis经常会丢掉一些数据,写进去了,过一会儿可能就没了。我的天,同学,你问这个问题就说明redis你就没用对啊。redis 是缓存,你给当存储了是吧?
啥叫缓存?用内存当缓存。内存是无限的吗,内存是很宝贵而且是有限的,磁盘是廉价而且是大量的。可能一台机器就几十个 G 的内存,但是可以有几个 T 的硬盘空间。redis 主要是基于内存来进行高性能、高并发的读写操作的。
那既然内存是有限的,比如redis就只能用 10G,你要是往里面写了 20G 的数据,会咋办?当然会干掉10G 的数据,然后就保留 10G 的数据了。那干掉哪些数据?保留哪些数据?当然是干掉不常用的数据,保留常用的数据了。
2)数据明明过期了,怎么还占用着内存?
这是由redis的过期策略来决定。redis 过期策略是:定期删除 + 惰性删除。
所谓定期删除,指的是redis默认是每隔100ms就随机抽取一些设置了过期时间的key,检查其是否过期,如果过期就删除。
假设redis里放了10w个key,都设置了过期时间,你每隔几百毫秒,就检查10w个key,那redis 基本上就死了,cpu负载会很高的,消耗在你的检查过期key上了。注意,这里可不是每隔100ms就遍历所有的设置过期时间的key,那样就是一场性能上的灾难。实际上redis是每隔100ms随机抽取一些key来检查和删除的。
但是问题是,定期删除可能会导致很多过期key到了时间并没有被删除掉,那咋整呢?所以就是惰性删除了。这就是说,在你获取某个key的时候,redis 会检查一下,这个 key如果设置了过期时间那么是否过期了?如果过期了此时就会删除,不会给你返回任何东西。
获取key的时候,如果此时key已经过期,就删除,不会返回任何东西。
答案是:走内存淘汰机制。
内存淘汰机制
redis 内存淘汰机制有以下几个:
- noeviction: 当内存不足以容纳新写入数据时,新写入操作会报错,这个一般没人用吧,实在是太恶心了。
- allkeys-lru: 当内存不足以容纳新写入数据时,在键空间中,移除最近最少使用的key(这个是最常用的)。
- allkeys-random: 当内存不足以容纳新写入数据时,在键空间中,随机移除某个key,这个一般没人用吧,为啥要随机,肯定是把最近最少使用的key给干掉啊。
- volatile-lru: 当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,移除最近最少使用的key(这个一般不太合适)。
- volatile-random: 当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,随机移除某个key。
- volatile-ttl: 当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,有更早过期时间的key优先移除。
参考